NSGA-II的原理解析及CODE实现
引言:权衡的哲学
在工程学、经济学乃至自然界的演化中,“最优”往往不是一个单一的极值,而是一组妥协。我们希望结构更轻但更强,投资回报更高但风险更低,神经网络精度更高但参数更少。
这些目标本质上是相互冲突的(Conflicting)。试图改善一个目标,往往意味着必须牺牲另一个目标。这种根本性的摩擦催生了 多目标优化(Multi-Objective Optimization, MOP) 的核心概念——帕累托最优(Pareto Optimality)。
与单目标优化寻找全局最小值不同,MOP 的目标是寻找一个解集——帕累托前沿(Pareto Front),代表了所有无法在不损害其他目标前提下改善某一目标的“完美权衡”状态。
本文将从第一性原理出发,解构该领域重要的里程碑:NSGA-II 。我们将探讨它们的设计哲学,数学基础,以及如何用代码实现它们。
NSGA-II的全称是 Non-dominated Sorting Genetic Algorithm II。中文通常翻译为:非支配排序遗传算法 II(或者第二代非支配排序遗传算法),它是由 K. Deb 等人在 2002 年提出的,是目前最流行、被引用次数最多的多目标进化算法之一。
第一部分:用直觉理解多目标优化
很多教程一上来就堆砌 $\mathbf{x} \in \Omega$ 和 $\nabla f(\mathbf{x})$,让人头大。我们不妨换个角度,把多目标优化想象成操作一个复杂的机器。
1.1 两个房间的故事:决策空间 vs. 目标空间
想象你在两个房间里工作,这两个房间通过一束看不见的电缆连接。
房间 A(决策空间 Decision Space):
这里有一个巨大的控制台,上面有许多旋钮和推杆。- 旋钮可能是:“机翼长度”、“材料厚度”、“发动机喷油量”。
- 你的每一个操作(一组旋钮的刻度),就是一个“解”,记为 $\mathbf{x}$。
房间 B(目标空间 Objective Space):
这里没有旋钮,只有墙上的几个显示屏。- 屏幕显示着:“飞行速度”、“耗油量”、“制造成本”。
- 屏幕上的数值,就是优化的“结果”,记为 $\mathbf{y}$。
关键难点:非线性映射
问题在于,这两个房间的关系是非常扭曲的。
你把“材料厚度”旋钮往右拧一点(决策空间微小变化),房间 B 里的“制造成本”可能猛增,而“安全性”却只增加了一点点。甚至,可能存在某种共振,稍微动一下旋钮,结果就天翻地覆。
NSGA 算法的工作,就是在这个黑盒子里,通过不断尝试拧旋钮,试图画出房间 B 里那些屏幕能达到的极限数值边界。
1.2 为什么会有冲突?(气球理论)
如果所有屏幕的数值能同时变好(速度越快、油耗越低、成本越低),那就不需要多目标优化了,只需要拼命拧旋钮就行。
但在现实中,这就像捏一个充满了水的气球。
- 你按下“成本”这一侧(试图降低成本),气球的另一侧“性能”就会鼓起来(性能变差)。
- 你按下“油耗”这一侧,另一侧“动力”就会鼓起来。
帕累托最优(Pareto Optimality) 的状态,就是你把这个气球压缩到了极限。再想按下去任何一点,其他地方就一定会鼓出来。这种“按不下去”的状态,就是我们要找的解。
1.3 帕累托支配:一种“无需纠结”的比较
在单目标世界里,5 比 3 大,这很简单。但在多目标世界里,怎么比大小?
我们用**“买车”来理解支配(Dominance)**。
假设我们要买车,只看两个指标:价格(越低越好) 和 速度(越快越好)。
情况一:完全碾压(支配 Dominance)
- 车 A: 10万,最高时速 200 km/h。
- 车 B: 15万,最高时速 150 km/h。
这里,车 A 此时就是 “支配” 了车 B。
- 价格:A 比 B 便宜(A 赢)。
- 速度:A 比 B 快(A 赢)。
结论: 理性人绝对不会买车 B。车 B 是劣质解,直接淘汰。
情况二:两难选择(互不支配 Non-dominated)
- 车 A: 10万,最高时速 200 km/h。
- 车 C: 8万,最高时速 180 km/h。
这就纠结了。
- 比价格?C 赢。
- 比速度?A 赢。
结论: A 和 C 互有胜负,谁也没法完全碾压谁。这时候,A 和 C 就是 “互不支配” 的。
NSGA 的目标:
找到一大堆像 A 和 C 这样“互不支配”的解,把那些像 B 一样被碾压的解全部扔掉。这一堆留下的解,连成一条线,就是帕累托前沿(Pareto Front)。
1.4 高维度的诅咒:当每个人都是冠军
NSGA-II 在处理 2 个或 3 个目标时很强,但为什么到了 4 个甚至 10 个目标(高维)时就失效了?
想象一个 100 人的班级。
- 如果只比“数学成绩”: 第一名只有一个,很容易排序。
- 如果比 10 个科目(数学、语文、体育、音乐、绘画…):
在多目标的高维空间里,每个人都能找到自己“赢”的那个点。
- 小明:虽然我数学差,但我体育好啊!(没被支配)
- 小红:虽然我体育差,但我唱歌好啊!(没被支配)
- 小强:虽然我啥都不行,但我打游戏第一啊!(没被支配)
结果就是: 在高维空间里,几乎所有解都是“互不支配”的。大家都在第一梯队(Rank 1)。
这时候,NSGA-II 的排序机制就失效了——因为它分不出谁更好。这就是为什么我们需要 NSGA-III,它不再单纯依赖“谁支配谁”,而是引入了“参考点”(Reference Points),像插旗子一样,强行在各个方向上保留最好的代表。这篇文章就不做展开介绍。
1.5 进化图谱:从 GA 到 NSGA 的血缘与革新
在深入 NSGA-II 的算法细节之前,我们必须先厘清它与标准遗传算法(Genetic Algorithm, GA)之间千丝万缕的联系。很多初学者误以为 NSGA 是一种全新的算法,但从第一性原理来看,NSGA 本质上是 GA 在多维空间的一种“特化变体”。
我们可以通过 “继承(Inheritance)” 和 “重构(Refactoring)” 这两个维度来解构它们的关系。
1.5.1 继承:不变的驱动引擎
如果把算法比作一辆赛车,那么 GA 和 NSGA 使用的是完全相同的底盘和引擎。这意味着,驱动种群在决策空间中进行“探索(Exploration)”和“开发(Exploitation)”的生物学算子并未发生改变。
- 编码方式 (Encoding): 无论是单目标的 GA 还是多目标的 NSGA,解的表示方法是一样的。对于连续优化问题,它们都使用实数编码;对于离散问题,都使用二进制或排列编码。
- 搜索算子 (Search Operators): 这是进化的动力源。
- 交叉 (Crossover): 如模拟二进制交叉 (SBX)。它的作用是混合父代基因,产生新的可能性。
- 变异 (Mutation): 如多项式变异 (Polynomial Mutation)。它的作用是随机扰动,防止算法陷入局部最优。
结论: 你在标准 GA 中学到的关于“如何产生新解”的知识,在 NSGA 中完全通用。
1.5.2 重构:评价机制的范式转移
GA 和 NSGA 的分道扬镳,发生在**“自然选择”**这一步。
标准 GA 的逻辑(标量霸权):
在单目标世界里,上帝是简单的。对于任意两个个体 $A$ 和 $B$,要么 $f(A) < f(B)$,要么 $f(A) > f(B)$。GA 只需要根据这个标量适应度(Fitness),使用轮盘赌或锦标赛选择,就能轻松决定谁该活下来。NSGA 的困境(向量迷局):
在多目标世界里,个体 $A$ 的得分为 $[10, 80]$,个体 $B$ 的得分为 $[20, 60]$。谁更好?GA 的标量比较逻辑失效了。如果你强行把它们加权求和(例如 $0.5f_1 + 0.5f_2$),你就把多目标退化回了单目标,这违背了寻找“多样化权衡解”的初衷。NSGA 的解决方案(虚拟适应度):
NSGA 没有改变 GA 的框架,而是重写了evaluate()和select()函数。它引入了一套**“虚拟适应度”**体系:- 等级 (Rank): 既然无法直接比大小,那就比“谁支配谁”。非支配排序将种群分层,Rank 1 的个体被视为“最强”。
- 拥挤度 (Distance): 在同等级别下,谁周围更空旷,谁的基因就更有保留价值(为了维持多样性)。
1.5.3 核心差异对比表
| 特性 | 标准 GA (Standard GA) | NSGA-II |
|---|---|---|
| 优化目标 | 单一目标函数 $\min f(x)$ | 目标向量 $\min \mathbf{F}(x)$ |
| 比较逻辑 | 标量比较 (Scalar Comparison) | 帕累托支配 (Pareto Dominance) |
| 适应度定义 | 直接等于目标函数值 (或其变换) | Rank (收敛性) + Crowding Distance (分布性) |
| 选择压力 | 优胜劣汰,只保留 $f(x)$ 最好的 | 分层淘汰,保留前沿面并维持稀疏分布 |
| 最终产出 | 全局最优解 (Global Optimum) | 帕累托最优解集 (Pareto Optimal Set) |
总结:
NSGA-II 并没有发明新的进化方式,它只是给传统的 GA 换了一个更聪明的“导航员”。这个导航员不再执着于寻找“唯一的王”,而是指挥种群去占领那条漫长而复杂的帕累托前沿防线。
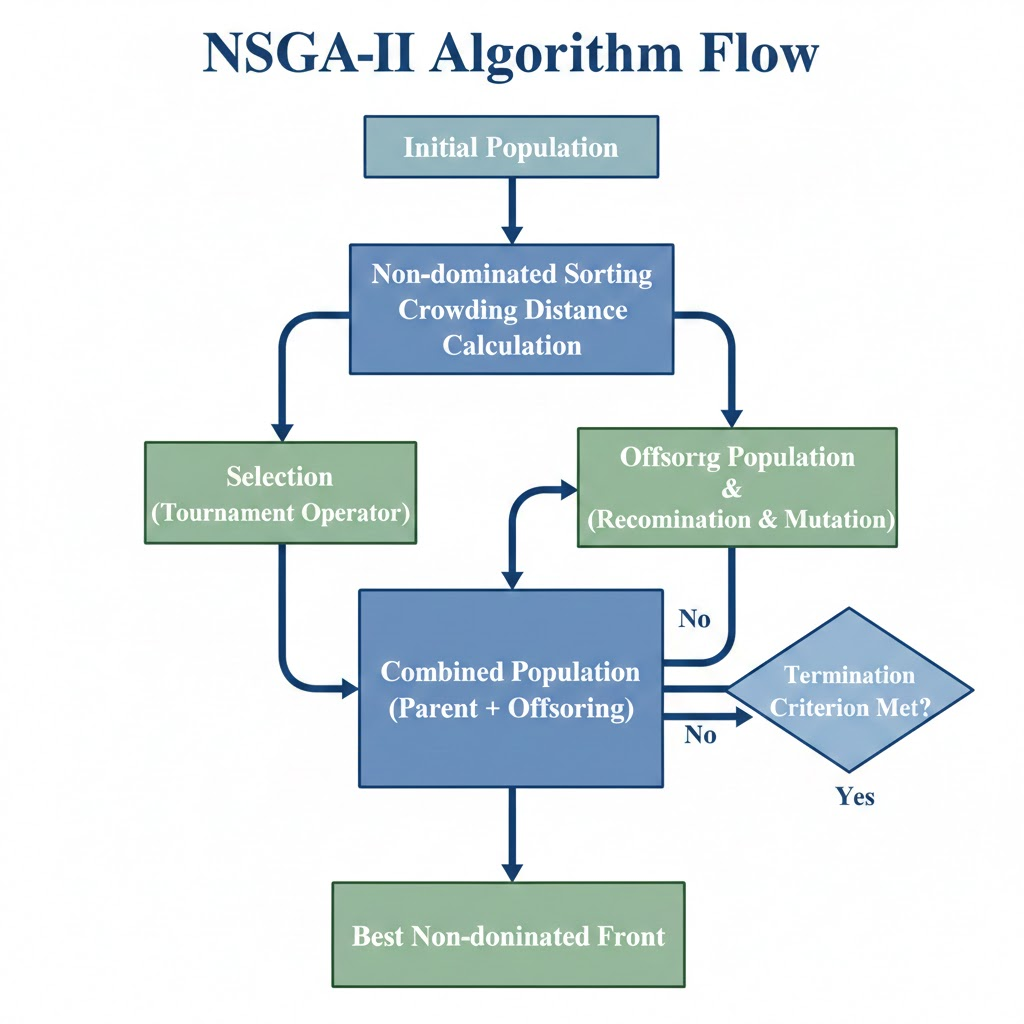
第二部分:NSGA-II原理介绍
Deb 等人在 2002 年提出的 NSGA-II 是进化计算领域的经典。它主要解决了初代 NSGA 的计算复杂度高、缺乏精英策略(Elitism)以及需要手动指定共享参数的问题。NSGA-II 建立在三大支柱之上:
- 快速非支配排序 (Fast Non-dominated Sorting): 建立收敛压力。
- 拥挤距离 (Crowding Distance): 维持种群多样性,无需参数。
- 精英保留策略 (Elitism): 防止优秀解在进化中丢失。
2.1 核心机制一:快速非支配排序 (The “Onion Peeling” Strategy)
想象一堆散落在桌子上的豆子(种群个体)。有些豆子在所有方面都比别的豆子大(支配),有些则互有胜负。
NSGA-II 的排序过程,就像是 “剥洋葱”。
步骤演示:
寻找第一层(Pareto Front 1):
找出所有“没有任何人能支配我”的豆子。把它们挑出来,放在一边,标记为 Rank 1(第一梯队)。这是目前最好的解集。寻找第二层(Pareto Front 2):
假设刚才拿走的 Rank 1 豆子都不存在了。在剩下的豆子里,再次寻找“没有任何人能支配我”的豆子。标记为 Rank 2。
注意:Rank 2 的豆子实际上是被 Rank 1 支配的,但在剩余的豆子里它们是最强的。重复剥离:
不断重复这个过程,直到所有豆子都被分了等级(Rank 1, Rank 2, Rank 3…)。
算法实现的技巧($O(N^2)$)
为了不让计算机算死(初代 NSGA 复杂度高达 $O(N^3)$),NSGA-II 采用了一个聪明的记账本策略:
- 支配计数 ($n_p$): 每个人记一个小本本,写上“有多少人比我强”。如果 $n_p=0$,说明没人比我强,我就是 Rank 1。
- 被支配集合 ($S_p$): 每个人再记一个名单,写上“我比哪些人强”。
剥皮逻辑:
- 先把所有 $n_p=0$ 的人请出列,归入当前 Front。
- 这些人离开时,通知他们名单 $S_p$ 里的所有人:“霸主走了,你们的 $n_p$ 减 1”。
- 如果某人的 $n_p$ 减到了 0,说明压在他头上的大山都没了,他晋升为下一层的霸主,加入 Next Front。
2.2 核心机制二:拥挤距离 (The “Social Distancing” Strategy)
如果只按 Rank 排序,大家都会争抢帕累托前沿中间那段最容易达到的位置,导致解集分布不均匀。
NSGA-II 引入了 拥挤距离(Crowding Distance),鼓励大家**“保持社交距离”**。
计算逻辑:
对于同一层级(同 Rank)的个体:
- 端点奖励: 处于极值点(比如最便宜的车、最快的车)的个体,距离设为无穷大 $\infty$。我们永远想保留探索边界的人。
- 中间计算: 对于中间的个体,它的拥挤距离等于它在所有目标维度上的“前后邻居”构成的长方体的周长。
$$
d_i = \sum_{m=1}^{M} \frac{f_m(i+1) - f_m(i-1)}{f_m^{max} - f_m^{min}}
$$
- 直观理解: 你的拥挤距离越大,说明你周围越空旷,你的存在越独特(稀缺资源)。
- 选择策略: 当两辆车 Rank 相同时,选那个周围没人的车(拥挤距离大的)。
2.3 精英保留的主循环 (Elitism Loop)
NSGA-II 的进化过程是一场残酷的 “父子混合大乱斗”。
常规遗传算法通常是用子代直接覆盖父代。但 NSGA-II 认为:如果老父亲比儿子强,就应该保留父亲。
流程图解:
- 父代 ($P_t$) + 子代 ($Q_t$) = 混合种群 ($R_t$)。
如果种群大小是 $N$,现在我们就有了 $2N$ 个个体。 - 全体排序: 对这 $2N$ 个个体进行“洋葱剥皮”分层。
- 填装新一代:
- 先把 Rank 1 的全部放入新种群。
- 如果没满,再把 Rank 2 的全部放入。
- …
- 临界层截断(关键): 假设放到 Rank 3 时,位置不够了。这时候,只在 Rank 3 内部,按照拥挤距离从大到小排序,把前几名塞进去,填满 $N$ 个位置为止。剩下的全部淘汰。
第三部分 Code实现
3.1 Matlab code实现
运行结果如图
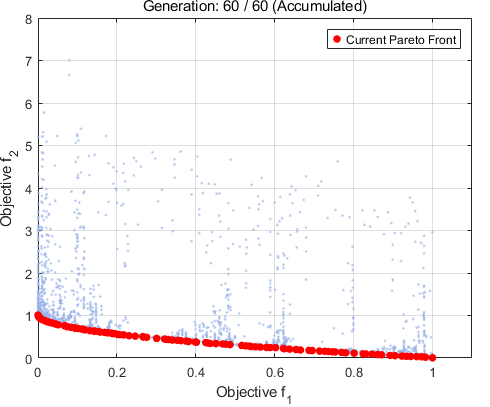
1 | |
3.2 Python code实现
运行结果如图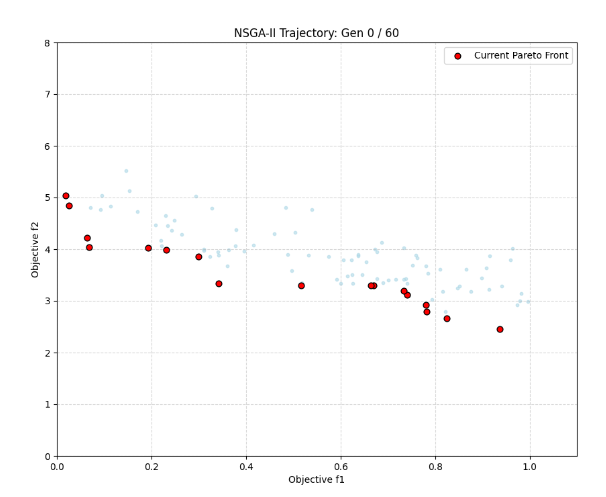
1 | |